What is E- Discovery? Part 5 - Production
 This is the last post in a series of five providing a roadmap for you to develop your own e-discovery plan. The first post provided an introduction to e-discovery and the E-Discovery Reference Model, which provides the framework for this blog series. The second post addressed the stages of Identification, Preservation, and Collection. The third post addressed Processing standards. The fourth post addressed Review, and this last post will cover Production.
This is the last post in a series of five providing a roadmap for you to develop your own e-discovery plan. The first post provided an introduction to e-discovery and the E-Discovery Reference Model, which provides the framework for this blog series. The second post addressed the stages of Identification, Preservation, and Collection. The third post addressed Processing standards. The fourth post addressed Review, and this last post will cover Production.
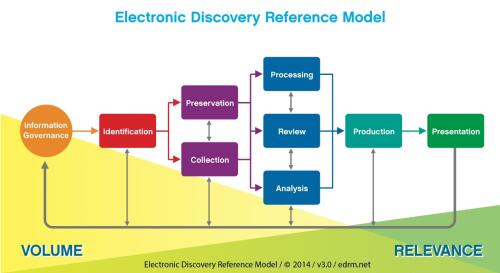
After review is complete, the next stage is Production. Regardless of your review method, you want to do what you’ve always done: Pull out the responsive documents and confirm you didn’t accidentally sweep in anything privileged. How you go about doing this will vary greatly based on whether or not you used review software. Even if you used review software, the processes for generating productions are all different. So instead of focusing on how to isolate your production set, we’re going to focus on what you’re going to give to opposing counsel and what you can expect to receive from opposing counsel.
The most important thing to remember about production is “what is good for the goose is good for the gander.” You should produce documents in a similar manner that your receive them. If production methods have not yet been discussed (for example, at a Rule 26(f) or Case Management conference), it’s not too late. Before you send anything out you can still check with the other side to see what they plan on producing. Because you want to exchange the same things. If opposing counsel is not going to give you metadata, you don’t want to give them metadata. And so forth.
There are many different methods or production and the E-Discovery reference model discusses standards for each of them. Productions generally come in the following format (or some combination thereof):
- PAPER - Please don’t produce e-discovery in paper! This helps no one and it’s expensive.
- PDF – If you’ll be producing in PDF format, you’ll need to decide whether you’re providing single or multipage PDFs and whether or not they’re text searchable.
- OCR (Optical character recognition) - These files make documents text searchable. If you are using review software, you may already have OCR text files. Confirm that vendors and software programs will take your redactions into account. You don’t want to redact a sentence out of the image, only to provide that same text in an OCR file.
- Single image tiffs with a load file (with or without OCR). These files will enable the recipient to load the documents into e-discovery software. Single image tiffs are image files, one document per page. The Load file tells the software where each document starts and ends and also identifies the metadata associated with each document. Load files can come in specialty formats (DII, DAT, OPT) or TXT or CSV format. You should be able to open all these (except for CSV) using NotePad. A CSV file (comma separated value) can be opened using Excel. Beware that load files can be difficult to interpret before you get the hang of it. Ask your vendor to help you decode them.
- Natives – it is pretty common to exchange native excels and other multimedia files. The documents should be renamed with the Bates Number.
If you don’t have document review software and you receive a production that is in Tiff/Load File Format with OCR, be aware that they contain a lot of usable information! You can ask a vendor to convert that load file to excel format, and ask them to convert those tiffs to multipage PDFs. Then you can review other parties’ productions in the same manner that we discussed above. Navigate through an excel file, and open PDFs as you go along.
The goal of this blog series was to de-mystify the process of e-Discovery by providing a basic overview. As you execute your e-discovery plan, you will likely develop your own methods and preferences. While the EDRM does provide guidelines and standards, there are many ways of doing things. Good luck!




