What is E-Discovery? Part 3 - Processing
 This is the third post in a series of five providing a roadmap for you to develop your own e-discovery plan. The first post provided an introduction to e-discovery and the E-Discovery Reference Model, which provides the framework for this blog series. The second post addressed the stages of Identification, Preservation, and Collection. This post will address Processing.
This is the third post in a series of five providing a roadmap for you to develop your own e-discovery plan. The first post provided an introduction to e-discovery and the E-Discovery Reference Model, which provides the framework for this blog series. The second post addressed the stages of Identification, Preservation, and Collection. This post will address Processing.
After you’ve collected electronic and hard copy documents from your client, the next stage is processing. Vendors “process” data by extracting the relevant metadata and providing the documents in a more user-friendly format. Vendors can also identify and remove corrupt file or files that may have viruses, weed out junk files or zero byte files, and they can also de-duplicate them (de-dupe) by eliminating exact digital copies. They can also run search terms against your documents (all or a sub-set) to identify the documents most likely to contain relevant information.
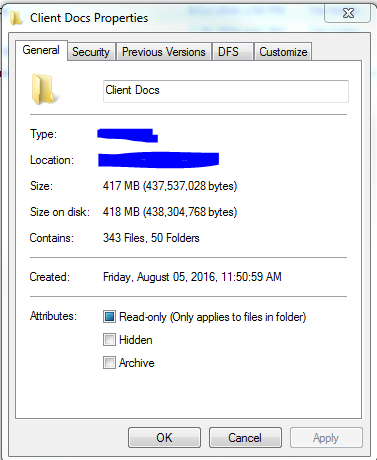
Before you approach a vendor to process your data, you need to know the size and format of your data. In terms of size, the vendor will want to know how many megabytes (MB) or gigabytes (GB) of data you have. To determine this, navigate to the folder or device containing your data. Right click the properties and determine the size. The screen shot below shows that the folder “Client Docs” contains 343 files totaling 417 MB. Your vendor is just looking for a ballpark figure, so for this data, I would say we have about 400 files totaling one half of a GB (1 GB = 1000 MB).
Your vendor will also want to know what kind of data you have. There are basically two types of e-documents: emails and loose e-documents. Email files are typically in PST (Microsoft Outlook) or MBOX (corporate or personal Gmail) format. These are compressed files, kind of like zip files of an email account. E-documents are everything else: Microsoft office files, PDFs, photos, videos, specialty files (e.g. AutoCAD drawings, QuickBooks exports).
Prior to processing, you’ll need to identify the metadata fields to capture and determine what numbering to use.
For metadata, the E-Discovery reference model provides a standard list of metadata fields and this is a great place to start. You may also want to include the following fields:
- BEGATT, ENDATT – These fields connect emails to their attachments. Emails and their attachments are also called families, where the email is the parent document and the attachments are the children. Emails will have field that shows the number of their attachments, and attachments will have a field that shows the number of the email they were attached to.
- CUSTODIAN – This identifies who or where the documents they came from. You may need to provide this to your vendor, depending on the collection method.
- Coding Fields – Coding fields are fields that you will have to fill in yourself. They can’t be extracted, because they involve subjective analysis.
- Summary
- Attorney Notes
- Document Description (letter, email, invoice, etc.)
- Responsive Designation
- Privilege Designation and Basis
- Confidentiality level
The vendor will also number the documents during processing. Each document or page will be assigned a unique number for reference. An internal number (or soft number) is just a reference number, like a bates number that’s not branded on the document. If you branded your internal number, you would end up with gaps in your production (as non-responsive and privileged documents are removed). An example of an internal number might be: revENRON-000368, with the eventual external number (also called hard number or production number) as ENRON-000008.
In our next post, we will cover review options.




